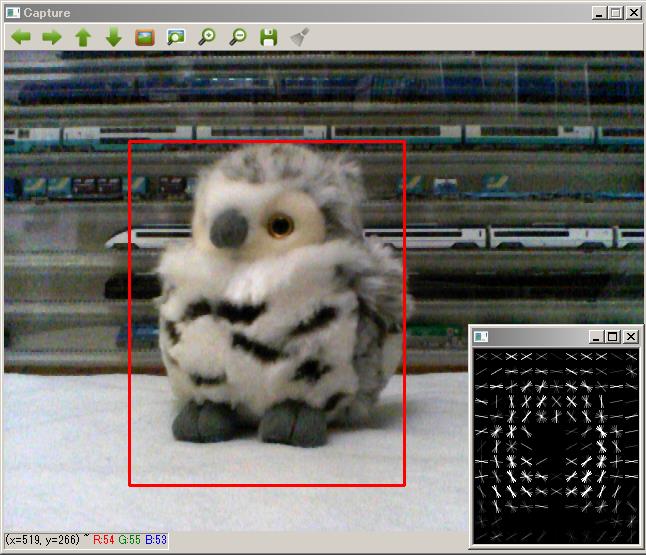
シマフクロウを検出する
今回は、カメラ画像から自分の好きな物体を検出する方法を紹介します。
最終的には上の画像のように、カメラ画像からシマフクロウを検出します。次のステップにより物体の検出を行います。
- 検出する物体の特徴を学習する
- 学習した特徴をもとに画像中の物体を探索する
まず、検出する物体の特徴を抽出するわけですが、どのような特徴を、どのように学習するか?が問題です。 これは画像処理や機械学習といった研究分野の問題で、面白いところではあるのですが、とても説明しきれないのでここでは説明省略します。
全てを説明しきれないので・・・ 詳細は、"Object Detection", "機械学習"などのキーワードで検索すると嫌というほど出てきます。または、最後にちょっとだけ原理に関わることも書きたいと思います。
今回は、HOG特徴をSVMで学習する方法で物体検出を行います。
HOG特徴は、輝度変化の方向をブロック毎に求めたものです。上の画像で、右下のウインドウに検出対象のHOG特徴を表示しています。
検出するフクロウは、カメラの向きなどによって様々な形状で写ります。そのため、フクロウの画像も(画像中でフクロウの写っている部分も)そのHOG特徴が変化します。 しかし、変化するといっても何らかの「フクロウらしさ」がHOG特徴に現れます。この「フクロウらしいHOG特徴」をSVMにより学習します。
画像処理と機械学習のライブラリ dlibを使う
物体検出(Object detection)の手法は、山ほどあり、日々新しい方法が開発されています。
またその実現方法も豊富で、どのライブラリをどのように組み合わせて作るか、といった選択もしなければなりません。
今回は、その中で特に簡単に、そして手っ取り早くできる方法として、画像処理と機械学習のライブラリ dlibを使用した画像検出を紹介します。
dlibはC++で書かれているので高速に動作することと、Pythonからも使えるようになっているので、簡単に試してみることができます。
物体検出にdlibのsimple_object_detectorを使用します。このサンプルがdlib/python_examples/train_object_detector.pyにあり、顔の検出を試すことができます。 また、C++のサンプルdlib/examples/train_object_detector.cpp 特にそのコメントにある説明も参考になります。
dlibのインストール
dlibをインストールします。
# pip install cython
# pip install scikit-image
# pip install dlib
またドキュメントやサンプルも見たいので、dlibのページから、dlibの.zipを持ってきて展開しておきます。
学習のための画像を用意する
フクロウHOG特徴を学習するために、フクロウの画像を50枚ほど準備します。
dlib/python_examplesの例では、20枚ほどの顔の画像から学習を行っています。数十枚の画像だけで学習するのは、他の手法と比べると少ない気もしますが、実際に試してみると案外うまく学習できます。
Webカメラの画像を1秒毎にjpgファイルに保存し、50枚ほど集めました。
カメラの連写機能を使ってもよいかと思います。うまく写っていない写真が混ざっていても問題ありません。
フクロウの画像を選択する
画像中のフクロウの領域を指定したXMLファイルを作る必要があるのですが、これを行う便利なツール"imglab"がdlibに入っています。これをビルドします。
$ cd ~/dlib-18.18/tools/imglab/
$ mkdir build
$ cd build
$ cmake ..
$ cmake --build . --config Release
実行ファイルimglabがビルドされました。 集めた写真は~/owlに入れてあります。
$./imglab -c ~/owl/all.xml ~/owl
これにより~/owlディレクトリにjpgファイルのxmlリストが作成されます。
$./imglab ~/owl/all.xml
imglabでall.xmlファイルを読み込んだGUIが起動します。ここで、Shift+マウスドラッグでフクロウを選択します。選択部分は赤線で表示されます。

これを学習させる全ての画像に対して行います。少々面倒な作業ですが、たぶん20~30枚ほど行えば十分でしょう。画像から物体がはみ出していたり、ぶれているなどしている画像では、領域選択しなければOKです。選択した領域だけから学習を行うからです。
imglabのメニューでFile->SaveAs を選択して"~/owl/training.xml"にXMLファイルを保存します。このXMLファイルは次のようになっています。
各画像で検出対象物の写っている領域が指定されているのがわかります。これで学習の準備は整いました。
HOG特徴をSVMに学習させる
以下のpythonコードを実行して集めた画像からHOG特徴を求め、認識させる物体のHOG特徴をSVMに学習させます。
import dlib
if __name__ == "__main__":
TrainingXml = "owl/training.xml"
SvmFile = "owl/detector.svm"
options = dlib.simple_object_detector_training_options()
options.add_left_right_image_flips = True
options.C = 5
options.num_threads = 4
options.be_verbose = True
dlib.train_simple_object_detector(TrainingXml, SvmFile, options)
細かいところは省略し、全てをdlibにお任せしているので、たったこれだけのコードです。
私のマシンでは、数秒で学習完了しました。学習結果がowl/detector.svmに保存されます。
カメラ画像で物体検出を行う
学習した特徴をもとにカメラ画像中の物体検出を行います。次のpythonコードを実行します。
if __name__ == "__main__":
SvmFile = "owl/detector.svm"
detector = dlib.simple_object_detector(SvmFile)
cap = cv2.VideoCapture(0)
if cap.isOpened() is not True:
raise("IO Error")
WinName = "Capture"
cv2.namedWindow(WinName, cv2.WINDOW_AUTOSIZE)
win_det = dlib.image_window()
win_det.set_image(detector)
while True:
ret, img = cap.read()
if ret:
rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
dets = detector(rgb)
if len(dets):
d = dets[0]
cv2.rectangle(img, (d.left(), d.top()), (d.right(), d.bottom()), (0, 0, 255), 2)
cv2.imshow(WinName, img)
if cv2.waitKey(1) > 0:
break
cap.release()
cv2.destroyAllWindows()
dlib.simple_object_detector()で作成したSVMを読み込んでいます。OpenCVのcap.read()関数でカメラ画像を採ってきて、
detector()で物体検出を行っています。
画像をcvtColor()関数で色変換していますが、これはOpenCVが扱うBGR画像からdlibが扱うRGB画像に変換しています。
しかし実際には、物体検出を行うときにモノクロ画像に変換されてしまうので、色変換しなくても動作します。
動画では、カメラを遠ざけたり近づけたりしていますが、フクロウ全体が写っているときには問題なく認識されています。
準備の手間が少なかった割に、結構うまく検出できています。
一方、カメラを傾けたときや、フクロウを横から写したときには認識されないことがわかります。これは、フクロウを横から見たときと前から見たときでは、違った模様の特徴をしており、検出手法からして尤もなことです。横から写っているときも検出したければ、別途横からの画像を集め、横からみたフクロウとして検出するなどの方策が必要です。
物体検出のアルゴリズムは?
実際のところ、dlibはどのように物体検出を行っているのか、気になるところでしょう。
なんとなく分かる/分かった気になれるかもしれない画像へのリンクを張っておきます。
人の(あなたの)画像認識能力の高さがわかるだけかもしれません・・・
ざっくりした説明: 学習により、切り出した画像中に対象物のHOG特徴の有無を判定できるSVMを作成します。検出時は、入力画像からHOGピラミッドを作成し、各画像におけるHOG特徴の有無をSVMで判定します。
dlibは、ドキュメントやサンプルを見ればライブラリの使用方法は理解できるものの、アルゴリズムの詳細がわかりにくいと感じました。 どのように実装されているのか詳細を知るには、ソースコードを見るしかないようです。
簡単、手軽に物体検出を行ってみる、今回のような場合は良いかもしれませんが、本当は学習パラメータを調整したり学習結果の評価も行わなければなりません。ドキュメントにおけるアルゴリズムの説明といえば、実装元の論文を紹介している程度しかありません。アプリケーションにぴったり適合させるために、細部を調整しながら作り込んでいくのはちょっと大変かもしれません。
もっと難しい目標だったり、色々カスタマイズしたい場合には、scikit-learnとOpenCVまたはscikit-imageを利用して自分で物体検出器を作る方が良いかもしれません。
実はOpenCVでHOGを求めてscikit-imageのSVMで学習することも実験済みなのですが、このページで紹介できるほど手軽ではないので、ここではdlibを使った方法を紹介しました。